Saturday, January 23, 2016
Thursday, January 14, 2016
Designing workflow with Airflow
I have been using Oozie for a while now and was a little dissatisfied with the tool in terms of managing the Hadoop jobs and not to mention debugging vague errors. While I was analyzing the substitute workflow engine, the Airflow by Aribnb caught my eye. I'll skip the introduction for now, you can read more about it here. This post highlights a its key features and demonstration of hadoop job.
Before I begin with the example, I'd like to mention the key advantages of Airflow over other tools:
- Amazing UI for viewing job flow(DAG), run stats, logs etc.
- You write an actual Python program instead of ugly configuration files
- Exceptional monitoring options of batch jobs
- Ability to query metadata and generate custom charts
- Contributors in the developer community have mostly worked/evaluated the other similar tools, thus it brings the best of everything as the tool evolves.
Monday, September 28, 2015
ETL with Apache Spark
In continuation to my previous post on Modern Data Warehouse Architecture, in this post I'll give an example using PySpark API from Apache Spark for writing ETL jobs to offload the data warehouse.
Spark is lightening-fast in data processing and works well with hadoop ecosystem, you can read more about Spark at Apache Spark home. For now, let's talk about the ETL job. In my example, I'll merge a parent and a sub-dimension (type 2) table form MySQL database and will load them to a single dimension table in Hive with dynamic partitions. When building a warehouse on hive, it is advisable to avoid snow-flaking to reduce unnecessary joins as each join task creates a map task. Just to raise the curiosity, the throughput on a stand alone Spark deployment for this example job is 1M+ rows/min.
Sunday, August 23, 2015
Apache Oozie Configuration with Hadoop 2.6.0
My idea of writing this post is to help people who are trying to install Oozie with Hadoop 2+ environment. As I had to refer different places for fixing the errors which I encountered during the process. Here's it goes..
Step 1: Download Oozie 4.1 from the Apache URL and save the tarball to any directory
Step 2: Assuming you have maven installed, if not, refer to the installation instructions here
Step 3: Update the pom.xml to change the default hadoop version to 2.3.0. The reason we're not changing it to hadoop version 2.6.0 here is because 2.3.0-oozie-4.1.0.jar is the latest available jar file. Luckily it works with higher versions in 2.x series
Step 4: Build Oozie executable
Step 5: The executable will be generated in the target sub directory under distro dir. Move it to a new folder under /usr/local/
Step 1: Download Oozie 4.1 from the Apache URL and save the tarball to any directory
cd ~/Downloads
tar -zxf oozie-4.1.0.tar.gz
sudo mv oozie-4.1.0 /usr/local/oozie-4.1.0Step 2: Assuming you have maven installed, if not, refer to the installation instructions here
Step 3: Update the pom.xml to change the default hadoop version to 2.3.0. The reason we're not changing it to hadoop version 2.6.0 here is because 2.3.0-oozie-4.1.0.jar is the latest available jar file. Luckily it works with higher versions in 2.x series
cd /usr/local/oozie-4.1.0
vim pom.xml
--Search for
<hadoop.version>1.1.1</hadoop.version>
--Replace it with
<hadoop.version>2.3.0</hadoop.version>Step 4: Build Oozie executable
mvn clean package assembly:single -P hadoop-2 -DskipTests Step 5: The executable will be generated in the target sub directory under distro dir. Move it to a new folder under /usr/local/
cd ~/Downloads/oozie-4.1.0/distro/target
tar -zxf oozie-4.1.0-distro.tar.gz
sudo mv oozie-4.1.0 /user/local/oozie-4.1.0Tuesday, August 18, 2015
Modern Data Warehouse Architecture
With the changing trends in the world of BI and the Big Data wave everywhere, a lot of organizations have started initiatives to explore how it fits in. To leverage the data ecosystem at it's fullest potential, it is necessary to think forward and ingest new technology pieces in the right place. That way, in a long run, both business and IT will reap its benefits.
Here's an interesting prediction by Gartner
" By 2020, information will be used to reinvent, digitalize or eliminate 80% of business processes and products from a decade earlier."
Imagine all the time, money and efforts you'll save off your existing data and infrastructure components if the Big Data implementation goes well. The architecture diagram below , is a conceptual design of how you can leverage the computation power of Hadoop ecosystem in your traditional BI / Data warehousing processes along with all the real time analytics and data science. They call it a data lake, warehouse is old school now.
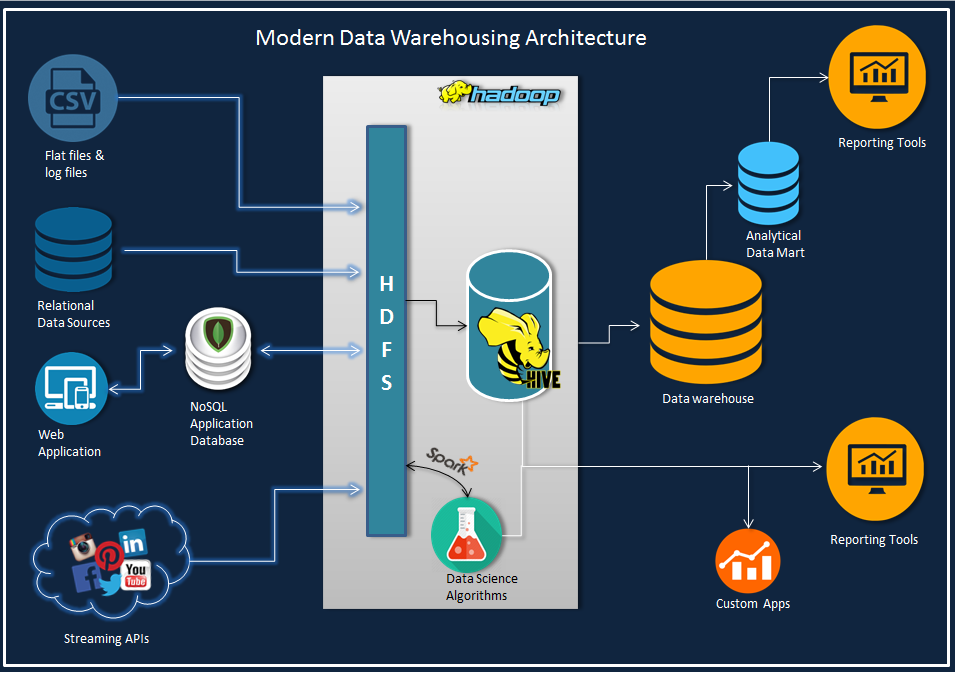
Alright, having a Hadoop ecosystem saves the computational time and provides all bells and whistles of real time analytics but "how does it save money?
Tuesday, February 17, 2015
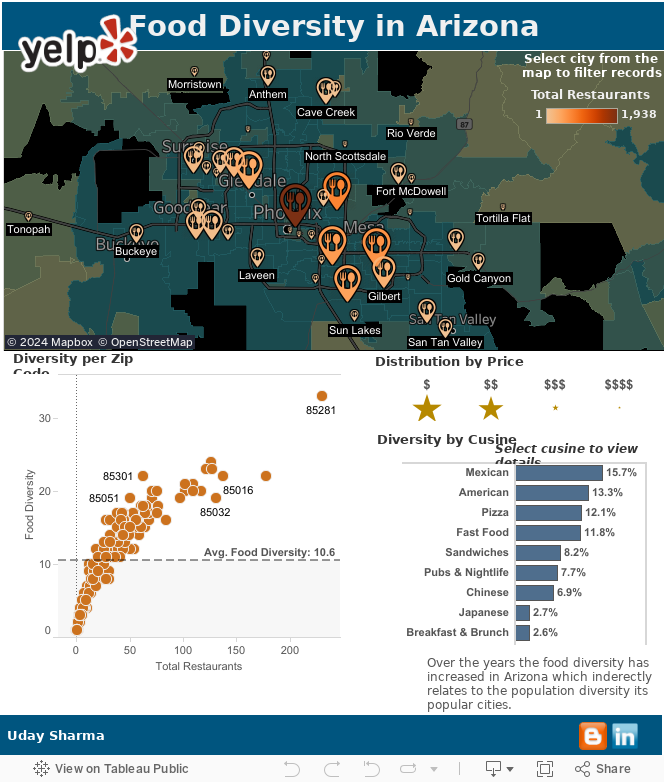
Twitter Sentiment Analysis
Sentiment Analysis in simple words is just reading between the lines of text, a very common technique you use when you read reviews about movies, restaurants etc. to make a choice. This technique is now being highly used by the organizations for pervasive analysis, customer profiling and accurate market campaigning.
While everyone was curiously waiting for the Delhi Elections 2015 results, during our casual discussion, me and my friend Harshit Pandey decided to find out the Tweet trends for the competing parties. We chose Twitter Streaming API as the source for our analysis, Mongo DB for archiving the Tweets, Python for performing sentiment analysis and Tableau Public for visualization.
Here's how it looks like, this dashboard shows the popular hashtags used by the users as well as the trends of the positive negative tweets (specific to each party) before and after the election results were announced.

Algorithm Used:
To perform the contextual analysis for each party within a tweet we wrote a custom method using decision trees for generating score for the two competing parties. We created a dictionary of biased hashtags and searched for their occurrence in the tweets. In addition to it we tokenized the tweet text based on the party name and searched for the occurrence of nearest positive or negative words and assigned the score accordingly. The code can be accessed from the Github repository.
Tuesday, February 3, 2015
Apache Drill: Writing SQL Queries on NoSQL Databases
Apache Drill is an amazing project by Apache foundation, specifically made to enrich the self-service analytics. It makes querying the semi structured data ridiculously easy for the Business Analysts and Data Scientists. You'd definitely love this if you are working with NoSQL database, Hadoop or scratching your head to write a code for reading a JSON file.
Subscribe to:
Comments
(
Atom
)