With the changing trends in the world of BI and the Big Data wave everywhere, a lot of organizations have started initiatives to explore how it fits in. To leverage the data ecosystem at it's fullest potential, it is necessary to think forward and ingest new technology pieces in the right place. That way, in a long run, both business and IT will reap its benefits.
Here's an interesting prediction by Gartner
" By 2020, information will be used to reinvent, digitalize or eliminate 80% of business processes and products from a decade earlier."
Imagine all the time, money and efforts you'll save off your existing data and infrastructure components if the Big Data implementation goes well. The architecture diagram below , is a conceptual design of how you can leverage the computation power of Hadoop ecosystem in your traditional BI / Data warehousing processes along with all the real time analytics and data science. They call it a data lake, warehouse is old school now.
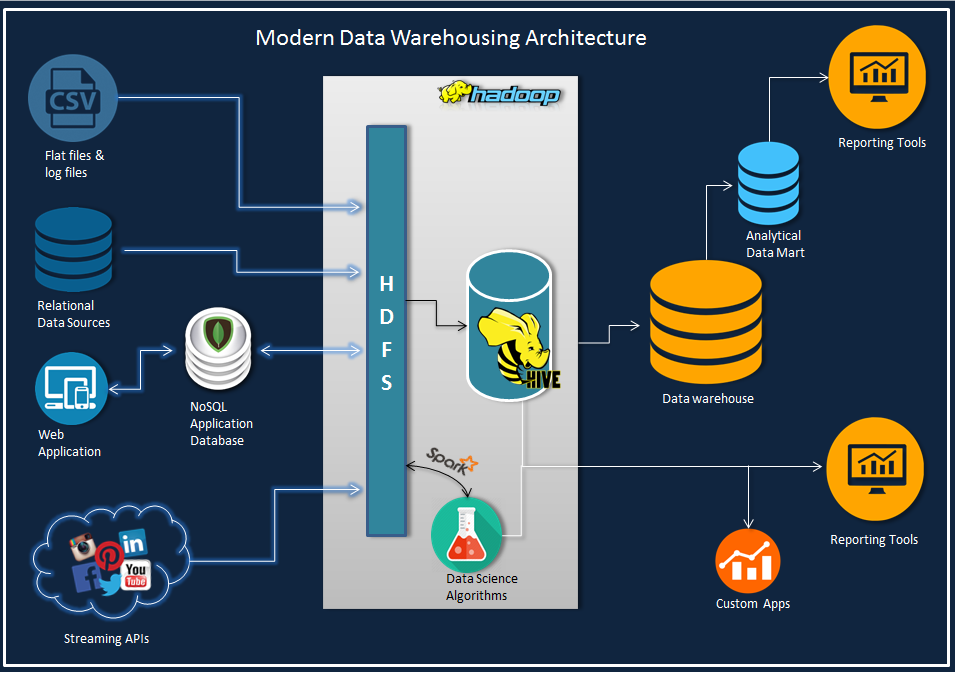
Alright, having a Hadoop ecosystem saves the computational time and provides all bells and whistles of real time analytics but "how does it save money?
" Rethink the volume of data you have and what you use for analysis, the price you pay to store the unused data, the efforts and money for version upgrades etc. To quantify, here's an example from [source]
"The Teradata Active Data Warehouse starts at $57,000 per Terabyte. In comparison, the cost of a supported Hadoop distribution and all hardware and datacenter costs are around $1,450/TB, a fraction of the Teradata price"

Keep 20-30% of Data in the Data warehouse and store the rest on Hadoop, hive-warehouse. You'll save a lot on the Database software licenses, server components and the performance overheads in processing information.
This indeed is a long term benefit, the low hanging fruit and need of the hour is the analysis on unstructured data you have or can collect from user reviews, social media posts, logs etc. Start with the below process and bring the data warehouse on board likewise.

No matter, which hadoop distribution you opt for, choose the deployment strategy considering all possible data landscapes in your enterprise to make most out of it.
Save on your IT budget, hire good talent!
Cheers!
Uday very good explanation but one more thing you can add on... As how your data move from diffrent disparate sources to your hadoop environment... You can achive the same by using spark-sql/spark-streaming/spark-core.
ReplyDeleteThanks Nilhal! Yes, there are variety of tools for pushing data to hadoop. I shall write another post for hadoop specific ETL tools.
ReplyDelete[…] continuation to my previous post on Modern Data Warehouse Architecture, in this post I’ll give an example using PySpark API from Apache Spark for writing ETL […]
ReplyDelete